Información general

Objetivos, características y beneficios
Los eventos son pequeñas unidades de datos compuestas por metadatos y un cuerpo que se generan al producirse un cambio significativo en el estado de un Sistema de Información. La arquitectura orientada a eventos o EDA (Event Driven Architecture), es el modelo que permite enviar estos eventos por toda la infraestructura del Sistema de Información.
La arquitectura EDA es un modelo de construcción de servicios y aplicaciones que se basa en el acoplamiento ligero que mantienen sus componentes. De esta manera, se permite simplificar los flujos de información, flexibilizarlos y gestionar los componentes que intervienen en el flujo de forma independiente, posibilitándose la construcción de Servicios Digitales tan rápidos que pueden operar con datos cercanos al tiempo real (Near Real Time).
Esta arquitectura se basa en el almacenamiento y la comunicación de los cambios de estado significativos en un sistema o aplicación. La diferencia entre una arquitectura EDA y un servicio de mensajería tradicional es que este tipo de arquitectura proporciona y gestiona los componentes que aportan cualidades como tolerancia a fallos, el reciclaje de eventos o el tratamiento de flujos de información casi en tiempo real.
Las características principales de una arquitectura basada en eventos son:
- Desacoplamiento: Los servicios sólo necesitan conocer dónde publicar los eventos o desde dónde consumirlos y no tiene que conocer la existencia del resto de servicios del sistema.
- Escalabilidad: El desacoplamiento entre servicios permite que tanto el publicador de eventos como el consumidor de eventos puedan dimensionarse de forma independiente, siendo esta característica potenciada al usarse con una arquitectura de microservicios.
- Granularidad: Cada evento y servicio se diseña con un único propósito.
- Reactividad: Los sistemas pueden reaccionar ante los eventos a gran velocidad pudiendo llegar a reaccionar casi a tiempo real.
Estas características repercuten en los siguientes beneficios a la hora de trabajar con eventos:
- Flexibilidad: El bajo acoplamiento e independencia de los componentes, los sistemas basados en arquitectura de eventos son flexibles pudiéndose añadir, eliminar o modificar componentes individuales sin impactar al resto del sistema.
- Tolerancia a fallos: El débil acoplamiento de las arquitecturas EDA conlleva que el fallo de un componente no tiene por qué implicar el fallo de todo el sistema, pudiendo el resto de los componentes operar con total normalidad.
- Desarrollos ágiles: Al ser componentes diseñados con un único propósito y con un bajo acoplamiento entre ellos, se simplifican los desarrollos, reduciendo los costes y el Time to Market.
A la hora de considerar los posibles problemas de las arquitecturas basadas en eventos deberemos contar los siguientes:
Complejidad: La gestión y coordinación de mensajes entre componentes desacoplados y distribuidos puede llegar a ser muy compleja.
Depuración y trazado de eventos: La depuración de un sistema distribuido y desacoplado puede resultar una tarea difícil
Principios
Partiendo de los principios generales definidos en la arquitectura global de contexto y que aplican en su totalidad a la arquitectura EDA, se definen un conjunto de principios específicos que se listan a continuación:
- Centrado en Eventos
- Enfoque asíncrono
(*) Puede consultarse el listado de Principios Tecnológicos Generales.
Centrado en Eventos
La arquitectura orientada a eventos considera el evento como un cambio en el estado o un hecho ocurrido dentro de un sistema o aplicación. Los eventos se usan para la comunicación asíncrona entre distintos componentes.
Desde el punto de vista de los eventos tenemos fuentes de eventos y consumidores, siendo las fuentes de eventos aquellos componentes que generan los eventos y los consumidores, aquellos componentes que reaccionan a los eventos.
Enfoque asíncrono
Los eventos ocurren y se consumen de forma asíncrona, de esta forma el productor no espera a que el evento sea consumido. El productor genera el evento, lo deposita en el canal y el consumidor lo lee del canal cuando está listo.
Esta forma de trabajar permite que tanto el productor como el consumidor actúen de manera independiente.
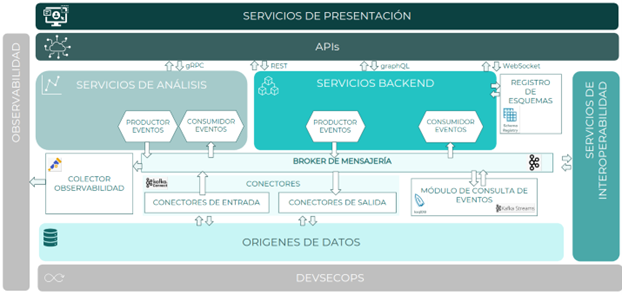
Componentes
A continuación, se muestra el diagrama de componentes identificados para una arquitectura orientada a eventos
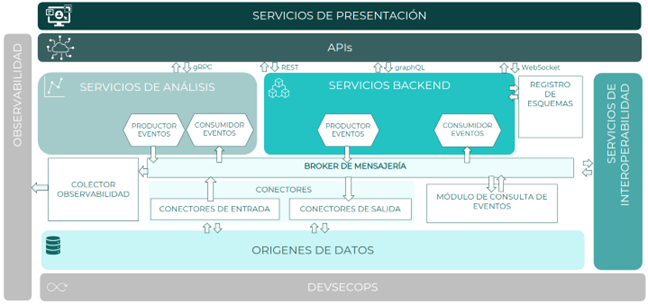
Productores de eventos
Los productores de eventos son los componentes responsables de generar los eventos de un sistema, pudiendo ser aplicaciones, servicios o dispositivos. Emitirán los eventos a un canal o tópico concreto dependiendo de su naturaleza y clasificación.
Consumidores de eventos
Los consumidores de eventos son los componentes encargados de consumir los eventos de un tópico, pudiendo ser aplicaciones, servicios o dispositivos.
Broker de mensajería
El broker de mensajería es el componente responsable de la gestión y enrutado de eventos, manteniendo el desacoplamiento de productores y consumidores.
Además, gestiona la seguridad de los eventos garantizando que solo aquellos productores o consumidores autorizados accedan a los datos.
Registro de esquemas
Es el componente que garantiza la fiabilidad y estructura de los datos que componen el evento. Valida y garantiza que, en todo momento, los datos escritos en el broker de mensajería por un productor van a poder ser leídos por un consumidor.
El registro de esquema almacena las diferentes versiones por la que evoluciona un esquema de datos y gestiona la compatibilidad hacía adelante o atrás, de estos datos con los componentes que tendrán que interpretarlos.
Si bien el registro de esquemas es opcional su uso es recomendable ya que permite un control o gobierno sobre la definición de los eventos y su evolución.
Conectores de salida
Son componentes específicos que permiten conectarse de forma no intrusiva con una tecnología que gestione información, por ejemplo una base de datos, extraerlos y enviar los cambios producidos como eventos al broker de mensajería.
Es similar a un productor de eventos y se utilizan cuando es necesario gestionar eventos producidos por un componente de terceros sin que sea necesario su evolución para realizar la producción de eventos.
Estos conectores pueden desarrollarse desde cero o utilizar soluciones Open Source maduras y fiables ya disponibles dentro de la comunidad de desarrolladores.
Conectores de entrada
Son componentes específicos que permiten enviar eventos de forma no intrusiva a un componente externo para que gestione o almacene esa información.
La información se extrae del broker de mensajería, por lo que es similar a un consumidor de eventos y se utilizan cuando es necesario enviar eventos a un componente de tercero sin necesidad de realizar adaptaciones ni modificaciones.
Estos conectores pueden desarrollarse desde cero o utilizar soluciones Open Source maduras y fiables ya disponibles dentro de la comunidad de desarrolladores.
Módulo de consulta de eventos
Componente que permite hacer búsquedas en un conjunto de eventos usando una sintaxis similar al de una base de datos. Simplifica la forma en la que se construyen, implementan y mantienen los componentes que realizan el procesamiento de flujos de eventos
Patrones de arquitectura y diseño
Patrones de eventos
Dependiendo de las características concretas de los servicios o aplicaciones a integrar de forma asíncrona, se identifican distintos patrones de diseño aplicables
- Publicador-Subscriptor
- Event Sourcing
- Flujo de eventos
- Pipeline de eventos
- Command Query Responsibility Segregation (CQRS)
- SAGA
- Dead Letter Queue (DLQ)
- Change Data Capture (CDC)
- Extract Transform Load (ETL)
- Outbox
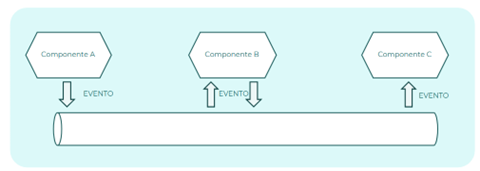
Publicador-Subscriptor
En este patrón un número indeterminado de productores generan eventos y los depositan en un canal. Por otra parte, un número indeterminado de consumidores obtienen los eventos depositados en el canal. En este patrón los eventos depositados en un canal están disponibles para todos los suscriptores.
Dado que la producción de eventos y el consumo de estos se produce de forma asíncrona, se obtiene un desacoplamiento entre publicadores y suscriptores, permitiéndose una alta escalabilidad por ambas partes.
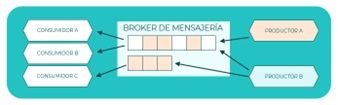
Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Patrón publicador / subscriptor
Event Sourcing
Según este patrón de diseño, el estado del sistema o de una aplicación es el resultado de una secuencia ordenada de eventos. Cada evento es un cambio en el estado de la aplicación por lo que es posible reconstruir el estado de la aplicación en cualquier punto en el tiempo. Para que la reconstrucción del estado a un momento dado sea posible es necesario que los eventos se establezcan como una secuencia de hechos inmutables.
Pongamos el ejemplo de una cuenta bancaria, el estado actual de la cuenta corriente será el resultado de todos los eventos de ingresos y cargos que han ocurrido sobre dicha cuenta a lo largo del tiempo. Para poder reconstruir el estado, cada evento de ingreso o cargo debe ser inmutable y debe estar ordenado como una secuencia de ocurrencia de los eventos, siendo así el estado en un momento dado será el resultado de todos los eventos evaluados secuencialmente desde el estado inicial hasta el momento indicado.
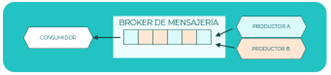
Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Patrón event sourcing
Flujo de eventos
El también conocido como stream de eventos (por su nombre en inglés), considera los eventos como un flujo constante que emana desde los productores de eventos y discurre hasta los consumidores de eventos. En este patrón los datos se consumen desde distintas fuentes en tiempo real, lo que a su vez permite el análisis de datos y la toma de decisiones en tiempo real.
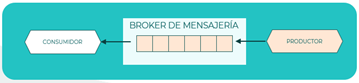
Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Flujo de eventos
Pipeline de eventos
Según este patrón de diseño sobre cada evento se aplica una secuencia ordenada de operaciones previos a su consumo. Por ejemplo, un evento que llega en formato XML y se desea convertir a JSON añadiendo a la información que contiene una serie de datos almacenados en un catálogo. En este contexto se tendrán dos pasos a realizar para cada evento que llegue: uno la transformación y el segundo el enriquecimiento del evento, tras lo cual el evento puede ser consumido.

Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Pipeline de eventos
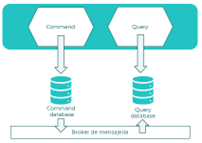
Command Query Responsibility Segregation (CQRS)
El patrón CQRS se utiliza en casos en los que sea necesario separar las responsabilidades de acceso y actualización de los datos.
Existe una base de datos de lectura basada en vistas que está asociada a tecnologías que permiten realizar accesos y búsquedas de forma eficiente (Elasticsearch, Mongo, Redis, …). Este modelo de datos mantendrá una réplica de solo lectura de esa información que necesitamos consultar, estando asociado únicamente a operaciones de tipo GET (select).
Por otro lado, el modelo de escritura utilizará bases de datos propietarias de los datos donde se realizarán las operaciones POST, PUT o DELETE (créate, update o delete).
Al existir dos modelos distintos de consulta y comandos, surge la necesidad de mantener actualizados los datos del modelo de lectura, realizándose para este caso una proyección de los datos. Usualmente se implementa mediante un enfoque orientado a eventos el envío de la información creada o actualizada a un tópico para realizar esa proyección, y existe un componente consumidor que gestiona esos eventos para crear o actualizar la información del modelo de lectura a partir de los datos actualizados del evento.
Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
- Fuente única de verdad
Referencia:
SAGA
El patrón Saga permite mantener la consistencia de datos en una transacción lógica compuesta por varios microservicios o componentes que actúan mediante una cadena de llamadas entre ellos. Este patrón representa una secuencia de transacciones locales donde, cada transacción local actualiza información dentro de un mismo microservicio.
Existen dos tipos de patrones Sagas:
Orquestados: Este tipo de Saga se caracteriza por tener una pieza central que controla todo el flujo de la petición. Los diferentes pasos del flujo no conocen nada del proceso y al finalizar vuelven a la pieza central que decide qué siguiente paso toca ahora.
Coreografiados: Este tipo de Saga se caracteriza por no tener pieza central, y los microservicios realizan una coreografía de operaciones, enviando un evento cuando termina cada transacción local, que lo recibe el siguiente servicio en realizar una operación en la transacción lógica.
Asociado a una transacción lógica definida mediante una Saga, se definen las operaciones de compensación en caso de que se produzca algún error o comportamiento no esperado en una transacción local de un microservicio. El objetivo de la compensación es revertir los cambios parciales que se puedan haber realizado como medio para mantener la consistencia de la información
.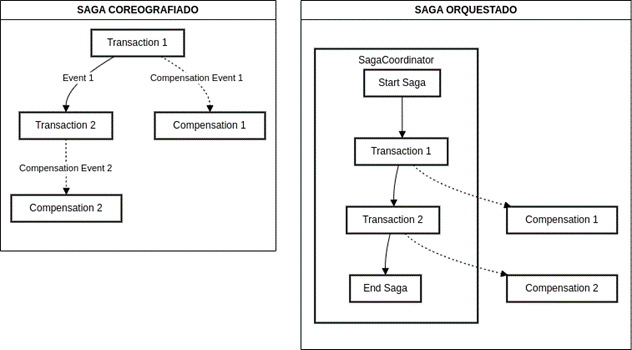
En estos ejemplos se representan las compensaciones de las transacciones locales según el tipo de saga.
En el SAGA Coreografiado cada transacción, en caso de fallo dispara la compensación. Como parte de esa compensación puede incluirse disparar la compensación de otras transacciones de forma que el resultado final sea consistente
En el SAGA Orquestado hay un SAGACoodinator que es el responsable de orquestar todas las transacciones locales y en caso de error lanzar todas las compensaciones locales que sean necesarias para garantizar la consistencia de los datos
Aunque en ambos casos el uso de eventos puede asociarse a la implementación de la Saga, suele asociarse más a las sagas coreografiadas que solo mediante eventos pueden realizar la coreografía de operaciones.
Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Pattern: Saga
Dead Letter Queue (DLQ)
Este patrón, también conocido como DLT (Dead Letter Topic), se aplica cuando no es posible procesar un evento y se desecha a un canal independiente que se llama Dead Letter Chanel. De esta forma, todos los eventos que no han podido procesarse ni se pierden ni colapsan el sistema con infinitos reintentos, sino que se centralizan todos en un único canal donde podrán recuperarse más delante.
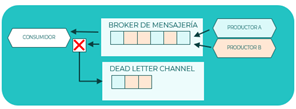
La recuperación de los eventos de la DLQ puede producirse lanzándolos directamente desde la DLQ o reintroduciéndolos en el topic, esta tarea de recuperación puede ser realizada bien de forma manual o bien mediante procesos automáticos.
Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Dead Letter Channel
Change Data Capture (CDC)
El patrón CDC convierte todos los cambios que ocurren en una base de datos en eventos que se publican en el broker de mensajería. Estos eventos pueden usarse para replicar el estado final de una base de datos en otro sistema, con fines analíticos o para procesamiento de casos de uso de negocio en tiempo real.
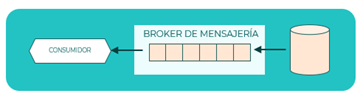
Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Change Data Capture
Extract Transform Load (ETL)
Este patrón define un mecanismo de tres pasos para realizar transformación de datos usando eventos. Los pasos son:
- Extraer información de una o varias fuentes de datos
- Transformar la información
- Almacenar la información
Cada paso generará una secuencia de eventos que permitirá llevar el flujo de información al siguiente paso.

Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Extract Transform Load
Outbox
Este patrón almacena el evento generado temporalmente en una base de datos antes de ser enviado al broker de mensajería. Los eventos almacenados son recuperados por un job que los envía masivamente al broker de mensajería.

Principios que aplican:
- Enfoque asíncrono
- Desacoplamiento de componentes
- Centrado en eventos
Referencia: Outbox
Patrones de observabilidad
Distributed tracing
Este patrón permite seguir el recorrido de un evento a través de su flujo, permitiendo ver los servicios internos y externos con los que el evento ha interaccionado.
Principios que aplican:
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Audit Logging
El propósito de este patrón es recoger las acciones que realiza un evento sobre todo cuando se propaga por un flujo complejo. Un log de auditoría se usa para ayudar a los responsables de calidad a seguir el flujo del evento y detectar un comportamiento sospechoso.
Cada log identifica al usuario, la acción que está realizando y el objeto de negocio.
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Exception tracking
Cuando se produce una excepción, es importante identificar la causa raíz. Una excepción es un síntoma de que algo no marcha bien. La forma tradicional de visualizar las excepciones es mirando los logs, sin embargo, una aproximación mejor es usar un servicio de seguimiento de excepciones.
Este patrón configura un servicio para reportar excepciones que permite hacer seguimiento de las excepciones duplicadas, alertas generadas y gestionar el manejo de excepciones.
- Calidad el servicio
- Resiliencia sobre recuperación
- Visibilidad & Trazabilidad
Pila tecnológica
| Componente | Solución | Descripción |
|---|---|---|
| Broker mensajería | Apache Kafka | Se utilizará Apache Kafka como broker de mensajería en su versión sin Zookeeper |
| Registro de esquemas | Apicurio | Se utilizará Apicurio como solución Schema Registry Compliant (Es decir que se ajusta a la especificación de Schema registry) como registro de esquemas. |
| Conectores de entrada | Apache Kafka Connect | Siempre que sea posible, se utilizarán módulos community u opensource (p.ej Debezium) de Apache kafka connect para implementar conectores de entrada. Deberá validarse que no existe un conector antes de abordar desarrollarlo desde cero. |
| Conectores de salida | Apache Kafka Connect | Siempre que sea posible, se utilizarán módulos community u opensource (p.ej Debezium) de Apache kafka connect para implementar conectores de salida. Deberá validarse que no existe un conector antes de abordar desarrollarlo desde cero. |
| Módulo de consulta de eventos | Apache Kafka Streams / Apache Flink Sql | Se utilizará de forma general Kafka streams como librería embebida en proyectos de consulta. En aquellos casos en los que se requiera una aproximación basada en consultas SQL se optará por Apache Flink SQL. |
| Observabilidad | ELK | Componente que permite gestionar la observabilidad. Se utilizará el framework de observabilidad ELK/EFK. Dentro de este componente se podrán utilizar librerías como OpenTelemetry para realizar la recopilación de datos necesaria para la pila de observabilidad. |
Escenarios de aplicación
Dado lo flexible y adaptable de las arquitecturas EDA se pueden aplicar en gran cantidad de escenarios mejorando el conocimiento, la eficiencia y la capacidad de respuesta. A continuación, desglosaremos algunos escenarios en los que se puede aplicar una arquitectura basada en eventos.
Automatización de procesos manuales
Escenario
Automatización de un proceso que se estaba realizando de forma manual. Por ejemplo, ingesta de datos de datos desde una Excel para registrarlo en una base de datos.
Descripción
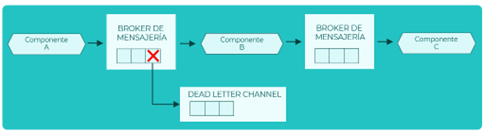
La automatización de procesos manuales se puede considerar una secuencia ordenada de pasos desde el inicio del proceso hasta su finalización. Los datos, convertidos en eventos, van evolucionando a su paso por el pipeline de eventos y si algún dato está corrupto o no se puede procesar se traslada al Dead Letter Channel.
Patrones
- Pipeline
- DLQ
Notificación de un cambio de estado a otro componente
Escenario
Tenemos un componente que a raíz de un cambio de estado interno debe notificarlo a otros componentes para que actualicen su estado en consecuencia.
Descripción
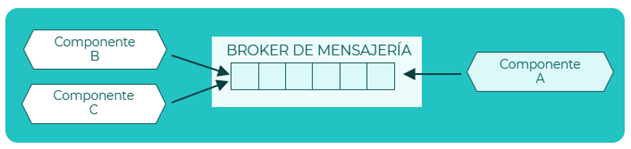
El componente A publica en el broker de mensajería un evento cuando se produce un cambio de estado interno. Los componentes B y C están conectados como consumidor al broker de mensajería y reciben estos eventos que producirán a su vez un cambio de estado en dichos componentes.
Patrones
- Publicador-Suscriptor
Monitorización de datos
Escenario
Monitorización de un componente para extraer información y calcular datos estadísticos con los que generar alertas
Descripción
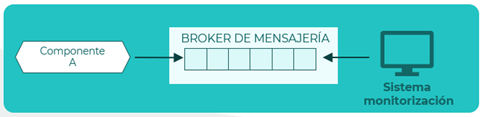
El componente genera una serie de eventos con la información que se quiere monitorizar. Estos eventos se mandan en un flujo al broker de mensajería para que los recoja el sistema de monitorización. El sistema de monitorización lo analiza y calcula los datos estadísticos que le permite genera alertas cuando sea necesario.
Patrones
- Flujo de eventos
Definición de transacciones
Escenario
Se va a definir una transacción distribuida entre tres microservicios usando para ello el patón SAGA coreografiado.
Descripción
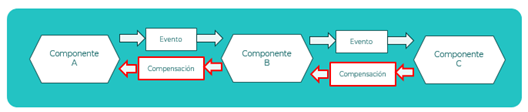
- Componente A: Inicia una transacción generando un evento que mandará los datos de inicio de transacción al broker de mensajería a un topic concreto. Entre los metadatos de la transacción se mandará el instante de inicio para poder garantizar un orden.
Se diseñará un consumidor que esté siempre revisando un topic concreto para ver si recibe orden de realizar una compensación para una transacción fallida. - Componente B: Constará de un consumidor que estará leyendo del topic donde ha escrito el componente A con los datos que inician la transición. Se creará un productor que, después de haber procesado la transacción, genere un evento a un topic para que la transacción pueda seguir su camino.
Se creará un consumidor que siempre estará revisando un topic concreto para ver si recibe orden de realizar una compensación para una transacción fallida. Se creará un productor que mandará los datos de su compensación al componente A que inició la transacción. - Componente C: Constará de un consumidor que estará leyendo del topic donde ha escrito el componente B con los datos que inician la transacción.
Se creará un productor que mandará los datos de su compensación al componente B que inició la transacción si fuese necesario al fallar la transacción.
Patrones
- SAGA (Coregrafiado)
Referencias
- Referencias técnicas: